Thèmes :
I. Transcription puis correction : une chaîne nécessaire
Les modèles de transcription vocale actuels sont très performants. La précision obtenue est souvent remarquable. Pourtant, des erreurs subsistent : ponctuation imparfaite, découpage des phrases, confusions lexicales ou mauvaise reconnaissance de certains termes techniques.
Une grande partie de ces erreurs peut être corrigée par un modèle de langage, à condition de lui fournir des instructions adaptées.
Si vous souhaitez comprendre plus en détail le fonctionnement de cette chaîne transcription-correction et son importance dans ma situation particulière, vous pouvez consulter l’article que j’ai consacré à ce sujet.
II. Architecture modulaire : maintenance et indépendance
J’utilise plusieurs logiciels de transcription et plusieurs interfaces différentes. J’ai également créé de nombreux raccourcis Apple qui intègrent des modules de correction.
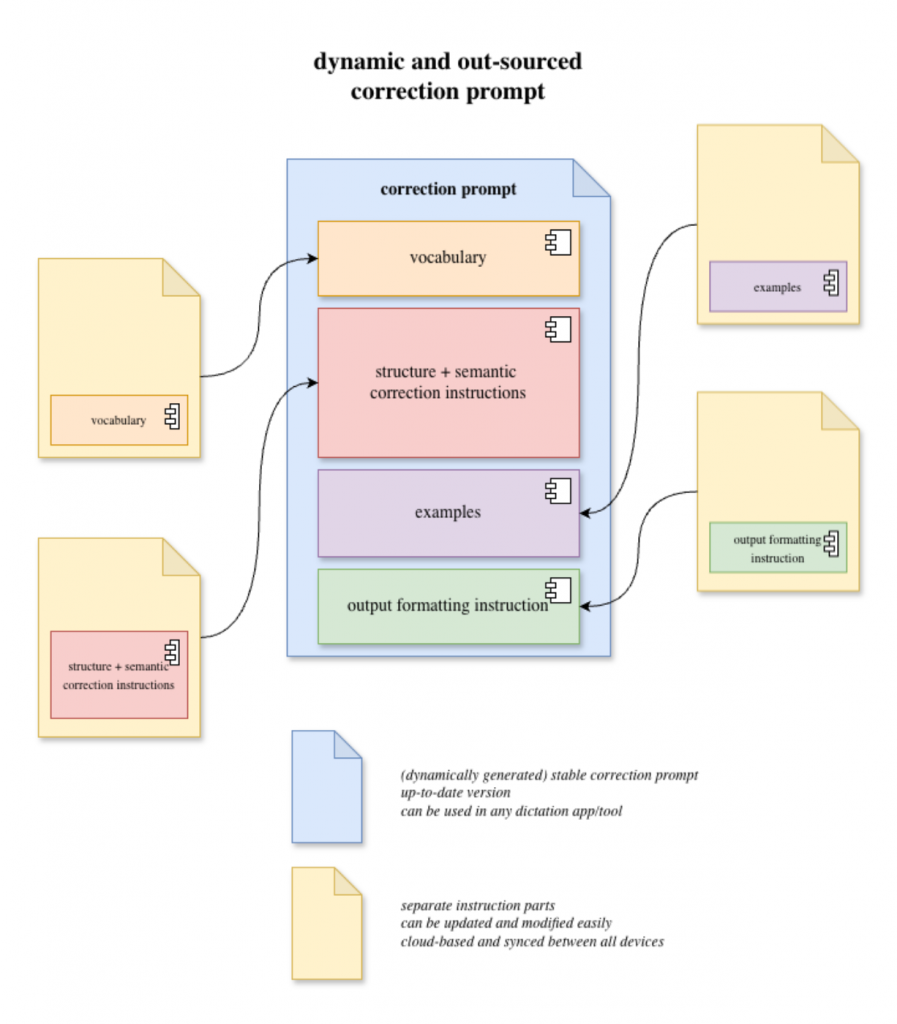
Au début, chaque modification du prompt — ajout d’un mot dans le vocabulaire, ajustement d’une règle, modification d’un exemple — devait être faite manuellement dans chaque logiciel et dans chaque raccourci. Cette méthode était lente et provoquait presque immanquablement des incohérences entre les versions. J’ai donc décidé de changer complètement l’organisation du système.
Au lieu de maintenir un seul bloc de texte, j’ai séparé le prompt en plusieurs fichiers :
- un fichier de vocabulaire
- un fichier d’instructions de correction
- un fichier d’exemples calibrants (few-shots)
Ces fichiers sont stockés dans un dossier iCloud. Cela permet :
- la synchronisation entre mes appareils
- l’exécution des raccourcis depuis Mac, iPhone ou iPad
- la modification centralisée du système
Cette organisation rend le système beaucoup plus simple à faire évoluer.
Indépendance vis-à-vis des outils
Cette architecture a aussi un avantage important : elle me rend indépendant des logiciels que j’utilise.
Les instructions, le vocabulaire et les exemples sont sous mon contrôle. Les logiciels de transcription deviennent simplement des environnements dans lesquels j’exécute ces instructions.
Chaque logiciel possède ses spécificités, ses atouts et ses limites, bien sûr, maisdans tous les cas, je conserve la maîtrise.Si un logiciel disparaît, devient payant ou ne me convient plus, je peux en changer sans reconstruire tout le système. Il suffit d’y injecter le prompt produit par mon compilateur.
Aujourd’hui, la plupart des logiciels de dictée vocale intègrent des fonctions de vocabulaire. Je préfère ne pas les utiliser pour éviter de réintroduire malgré moi des problèmes de version et de mise à jour que je cherche précisément à éviter. Dans le compilateur que vous pourrez trouver à la fin de cet article, j’ai tout de même intégré une option permettant de ne pas intégrer le vocabulaire au prompt final si vous préférez laisser les interfaces de dictée gérer cette partie de la correction.
La logique du travail reste la même, même si les outils changent.
III. Compilation et déclinaisons
Pour assembler les différents fichiers, j’ai créé un raccourci Apple qui joue le rôle de compilateur. Son fonctionnement est simple :
- lecture des fichiers
- assemblage des blocs
- production d’un prompt complet
Le raccourci ne contient pas le prompt lui-même. Il se contente de lire les fichiers et de les assembler. Cela évite toute duplication et garantit que toutes les versions du prompt reposent sur les mêmes sources.
Cette structure permet aussi de créer facilement des variantes. Il suffit de dupliquer le raccourci et de modifier les instructions utilisées.
Je conserve également un dossier backups contenant différentes versions des fichiers d’instruction. Cela me permet d’expérimenter — en ajoutant ou en modifiant certaines instructions, en particulier — sans risquer de casser l’ensemble du système.
IV. Organisation des fichiers
Les fichiers sont regroupés dans un dossier « reconnaissance vocale » dans mon espace iCloud :
- vocabulaire
- instructions
- exemples
- dossier backups
Le compilateur lit ces fichiers, assemble les éléments et copie le prompt final dans le presse-papiers. Je peux ensuite le coller dans n’importe quel logiciel de transcription ou interface d’IA.
Ce qui était au départ une solution ponctuelle est devenu une petite infrastructure personnelle pour la correction de dictée vocale. Elle me permet d’expérimenter, d’améliorer mes outils et d’éviter de repartir de zéro à chaque modification.
Mise à jour Avril 2026
V. Automatisation de la mise à jour des logiciels de dictée
Depuis la première version de cette architecture, j’ai ajouté une couche supplémentaire d’automatisation. Le système ne se contente plus de compiler un prompt complet à partir de fichiers externalisés : il peut désormais mettre à jour directement certains logiciels de dictée que j’utilise au quotidien.
Le vocabulaire reste maintenu dans un fichier JSON structuré par catégories. Pour faciliter son enrichissement, j’ai créé un petit service macOS accessible depuis le clic droit sur un mot sélectionné. Il permet d’ajouter rapidement un terme au fichier de vocabulaire, de choisir la catégorie correspondante, de préciser si nécessaire une forme canonique, puis de vérifier que le terme n’existe pas déjà afin d’éviter les doublons.
Le compilateur assemble ensuite les différents fichiers : instructions générales, vocabulaire et exemples calibrants. Le prompt final est produit automatiquement à partir de ces sources, sans qu’il soit nécessaire de modifier à la main un bloc de texte dans chaque application.
Un second script de synchronisation propage ensuite ce prompt compilé vers plusieurs logiciels de dictée, notamment SuperWhisper, Spokenly et Sophist. Ces applications deviennent ainsi des points d’utilisation d’un même prompt de référence, plutôt que des lieux où maintenir manuellement des variantes indépendantes.
J’ai également ajouté une automatisation macOS qui exécute cette synchronisation deux fois par semaine. Je peux toujours lancer la mise à jour manuellement lorsque je viens de modifier le vocabulaire ou les instructions, mais le système dispose aussi d’un mécanisme régulier de remise à jour.
Cette évolution renforce l’idée centrale de l’architecture : les règles de correction ne sont plus enfermées dans un logiciel particulier. Elles restent dans des fichiers que je contrôle, que je peux modifier, sauvegarder, versionner et réutiliser. Les logiciels de dictée ne sont plus le centre du système ; ils deviennent des interfaces d’exécution branchées sur une base commune d’instructions.
Ressources
- Kit d’installation complet
- raccourci Apple « compilateur »
- dossier contenant des fichiers d’exemple à compiler.
Dans un prochain article, je détaillerai le fonctionnement de mon raccourci de transcription-correction et à ses possibilités d’intégration. Ce raccourci fonctionne sur la même logique et utilise pour fonctionner les mêmes fichiers que le compilateur.